Tracing the Python GIL
Tracing and visualizing the Python GIL with perf and VizTracer



- Why the GIL matters
- Why I write this
- Prerequisites
- Track thread or process states via perf
- VizTracer
- Mixing VizTracer and perf output
- Detecting the GIL
- Releasing the Kraken... ehm GIL
- Jupyter integration
- Conclusion
- TLDR
- Future plans
Why the GIL matters
There are plenty of articles explaining why the Python GIL (The Global Interpreter Lock) exists1, and why it is there. The TLDR version is: the GIL prevents multithreaded pure Python code from using multiple CPU cores.
However, in Vaex we execute most of the CPU intensive parts in C (C++) code, where we release the GIL. This is a common practice in high-performance Python libraries, where Python acts merely as a high-level glue.
However, the GIL needs to be released explicitly, and this is the responsibility of the programmer and might be forgotten, leading to suboptimal use of your machine.
I recently had this issue in Vaex where I simply forgot to release the GIL and found a similar issue in Apache Arrow2.
Also, when running on 64 cores, I sometimes see a performance in Vaex that I am not happy with. It might be using 4000% CPU, instead of 6400% CPU, which is something I am not happy with. Instead of blindly pulling some levers to inspect the effect, I want to understand what is happening, and if the GIL is the problem, why, and where is it holding Vaex down.
Why I write this
I'm planning to write a series of articles explaining some tools and techniques available for profiling/tracing Python together with native extensions, and how these tools can be glued together, to analyze and visualize what Python is doing, and when the GIL it taken or dropped.
I hope this leads to improvement of tracing, profiling, and other performance tooling in the Python ecosystem, and the performance of the whole Python ecosystem.
Prerequisites
Linux
Get access to a Linux machine, and make sure you have root privileges (sudo is fine), or ask your sysadmin to execute some of these commands for you. For the rest of the document, we only run as user.
Perf
Make sure you have perf installed, e.g. on Ubuntu:
$ sudo yum install perfKernel configuration
To enable running it as a user:
# Enable users to run perf (use at own risk)
$ sudo sysctl kernel.perf_event_paranoid=-1
# Enable users to see schedule trace events:
$ sudo mount -o remount,mode=755 /sys/kernel/debug
$ sudo mount -o remount,mode=755 /sys/kernel/debug/tracingPython packages
We will make use of VizTracer and per4m
$ pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"Track thread or process states via perf
There is no way to get the GIL state in Python 1 since there is no API for this. We can track it from the kernel, and the right tool for this under Linux is perf.
Using the linux perf tool (aka perf_events), we can listen to the state changes for processes/threads (we only care about sleeping and running), and log them. Although perf may look scary, it is a powerful tool. If you want to know a bit more about perf, I recommend reading Julia Evans' zine on perf or go through Brendan Gregg's website.
To build our intuition, we will first run perf on a very trivial program:
Except using polling https://github.com/chrisjbillington/gil_load/↩
import time
from threading import Thread
def sleep_a_bit():
time.sleep(1)
def main():
t = Thread(target=sleep_a_bit)
t.start()
t.join()
main()
We listen to just a few events to keep the noise down (note the use of wildcards):
$ perf record -e sched:sched_switch -e sched:sched_process_fork \
-e 'sched:sched_wak*' -- python -m per4m.example0
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0,032 MB perf.data (33 samples) ]And use the perf script command to write human/parsable output.
$ perf script
:3040108 3040108 [032] 5563910.979408: sched:sched_waking: comm=perf pid=3040114 prio=120 target_cpu=031
:3040108 3040108 [032] 5563910.979431: sched:sched_wakeup: comm=perf pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563910.995616: sched:sched_waking: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995618: sched:sched_wakeup: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995621: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995622: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995624: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R+ ==> next_comm=kworker/31:1 next_pid=2502104 next_prio=120
python 3040114 [031] 5563911.003612: sched:sched_waking: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.003614: sched:sched_wakeup: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.083609: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083612: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083613: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R ==> next_comm=ksoftirqd/31 next_pid=198 next_prio=120
python 3040114 [031] 5563911.108984: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.109059: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.112250: sched:sched_process_fork: comm=python pid=3040114 child_comm=python child_pid=3040116
python 3040114 [031] 5563911.112260: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112262: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112273: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112418: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112450: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112473: sched:sched_wake_idle_without_ipi: cpu=31
swapper 0 [031] 5563911.112476: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112485: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112485: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112489: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112496: sched:sched_switch: prev_comm=python prev_pid=3040116 prev_prio=120 prev_state=S ==> next_comm=swapper/37 next_pid=0 next_prio=120
swapper 0 [031] 5563911.112497: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
swapper 0 [037] 5563912.113490: sched:sched_waking: comm=python pid=3040116 prio=120 target_cpu=037
swapper 0 [037] 5563912.113529: sched:sched_wakeup: comm=python pid=3040116 prio=120 target_cpu=037
python 3040116 [037] 5563912.113595: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563912.113620: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031Take a moment to digest the output. I can see a few things. Looking at the 4th column (time in seconds), we can see where the program slept (it skips 1 second). Here we see that we enter the sleeping state with a line like:
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
This means the kernel changed the state of the Python thread to S (=sleeping) state.
A full second later, we see it being woken up:
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Of course, you need to build some tooling around this, to really see what is happening. But one can imagine this output can be easily parsed and this is what per4m does. However, before we go there, I'd first like to visualize the flow of a slightly more advanced program using VizTracer.
VizTracer
VizTracer is a Python tracer that can visualize what your program does in the browser. Let us run it on a slightly more advanced example to see what it looks like.
import threading
import time
def some_computation():
total = 0
for i in range(1_000_000):
total += i
return total
def main():
thread1 = threading.Thread(target=some_computation)
thread2 = threading.Thread(target=some_computation)
thread1.start()
thread2.start()
time.sleep(0.2)
for thread in [thread1, thread2]:
thread.join()
main()
Running viztracer gives output like:
$ viztracer -o example1.html --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Generating HTML report
Report saved.And the HTML should render as:
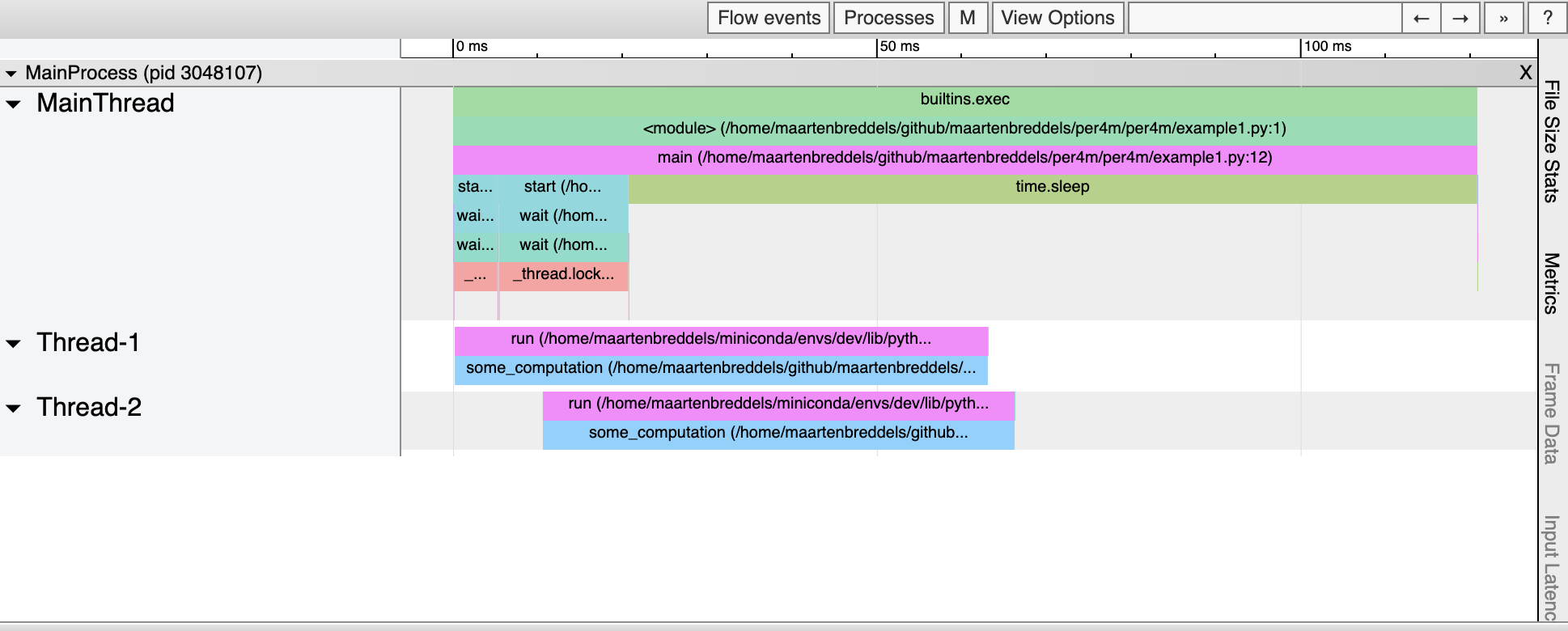
From this, it seems that some_computation seem to be executed in parallel (twice), while in fact, we know the GIL is preventing that. So what is really going on?
Mixing VizTracer and perf output
Let us run perf on this, similarly to what we did to example0.py. However, we add the argument -k CLOCK_MONOTONIC so that we use the same clock as VizTracer and ask VizTracer to generate a JSON, instead of an HTML file:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' \
-k CLOCK_MONOTONIC -- viztracer -o viztracer1.json --ignore_frozen -m per4m.example1Then we use per4m to translate the perf script results into a JSON that VizTracer can read
$ perf script | per4m perf2trace sched -o perf1.json
Wrote to perf1.jsonNext, use VizTracer to combine the two JSON files.
$ viztracer --combine perf1.json viztracer1.json -o example1_state.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.This gives us:
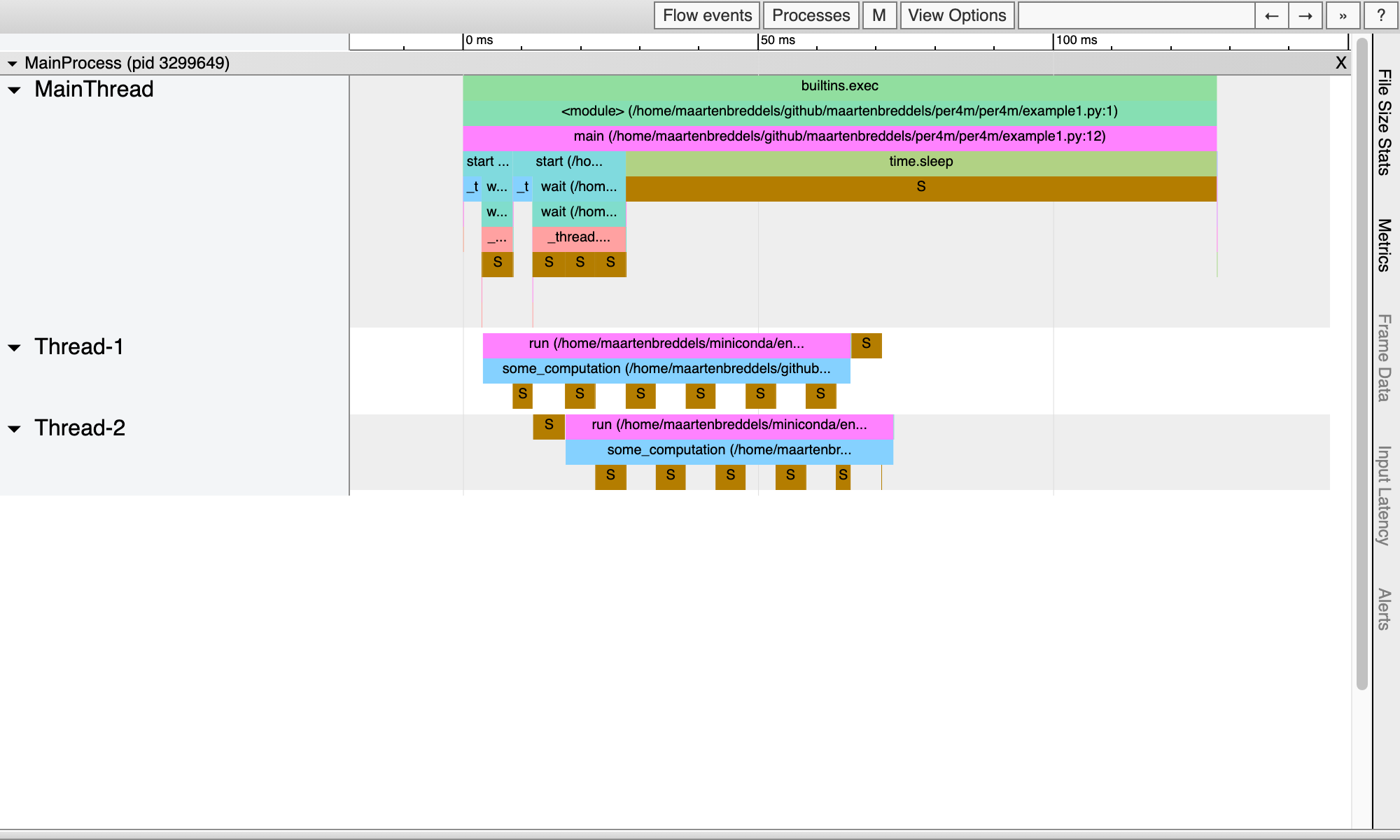
From this visualization, it is clear the threads regularly enter a sleeping state due to the GIL and do not execute in parallel.
Detecting the GIL
We see our process sleeping, but we do not see any difference between the sleeping state being triggered by calling time.sleep and due to the GIL. There are multiple way to see the difference, and we will present two methods.
Via stack traces
Using perf record -g (or better perf record --call-graph dwarf which implies -g), we get stack traces for each event of perf.
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*'\
-k CLOCK_MONOTONIC --call-graph dwarf -- viztracer -o viztracer1-gil.json --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/viztracer1-gil.json ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Report saved.
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0,991 MB perf.data (164 samples) ]Looking at the output of perf script (where we add --no-inline for performance reasons), we get a load of information. Looking at a state change event, we can now see that take_gil was called!
$ perf script --no-inline | less
...
viztracer 3306851 [059] 5614683.022539: sched:sched_switch: prev_comm=viztracer prev_pid=3306851 prev_prio=120 prev_state=S ==> next_comm=swapper/59 next_pid=0 next_prio=120
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4b92 schedule+0x42 ([kernel.kallsyms])
ffffffff9654a51b futex_wait_queue_me+0xbb ([kernel.kallsyms])
ffffffff9654ac85 futex_wait+0x105 ([kernel.kallsyms])
ffffffff9654daff do_futex+0x10f ([kernel.kallsyms])
ffffffff9654dfef __x64_sys_futex+0x13f ([kernel.kallsyms])
ffffffff964044c7 do_syscall_64+0x57 ([kernel.kallsyms])
ffffffff9700008c entry_SYSCALL_64_after_hwframe+0x44 ([kernel.kallsyms])
7f4884b977b1 pthread_cond_timedwait@@GLIBC_2.3.2+0x271 (/usr/lib/x86_64-linux-gnu/libpthread-2.31.so)
55595c07fe6d take_gil+0x1ad (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfaa0b3 PyEval_RestoreThread+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c000872 lock_PyThread_acquire_lock+0x1d2 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe71f3 _PyMethodDef_RawFastCallKeywords+0x263 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d657 call_function+0x3b7 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c074e5d builtin_exec+0x33d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7078 _PyMethodDef_RawFastCallKeywords+0xe8 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c066c39 _PyEval_EvalFrameDefault+0x6549 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb77e0 _PyEval_EvalCodeWithName+0xc80 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b62 _PyFunction_FastCallKeywords+0x582 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb81e2 PyEval_EvalCode+0x22 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0c51d1 run_mod+0x31 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf31d PyRun_FileExFlags+0x9d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf50a PyRun_SimpleFileExFlags+0x1ba (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d05f0 pymain_main+0x3e0 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d067b _Py_UnixMain+0x3b (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
7f48849bc0b2 __libc_start_main+0xf2 (/usr/lib/x86_64-linux-gnu/libc-2.31.so)
55595c075100 _start+0x28 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
...pthread_cond_timedwait is called, this is what https://github.com/sumerc/gilstats.py uses for a eBPF tool, in case you are interested in other mutexes.
_PyEval_EvalFrameDefault etcetera instead. I plan to write how to inject Python stacktraces in a future article.
The per4m perf2trace convert tool understands this and will generate different output when take_gil is in the stacktrace:
$ perf script --no-inline | per4m perf2trace sched -o perf1-gil.json
Wrote to perf1-gil.json
$ viztracer --combine perf1-gil.json viztracer1-gil.json -o example1-gil.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.This gives us:
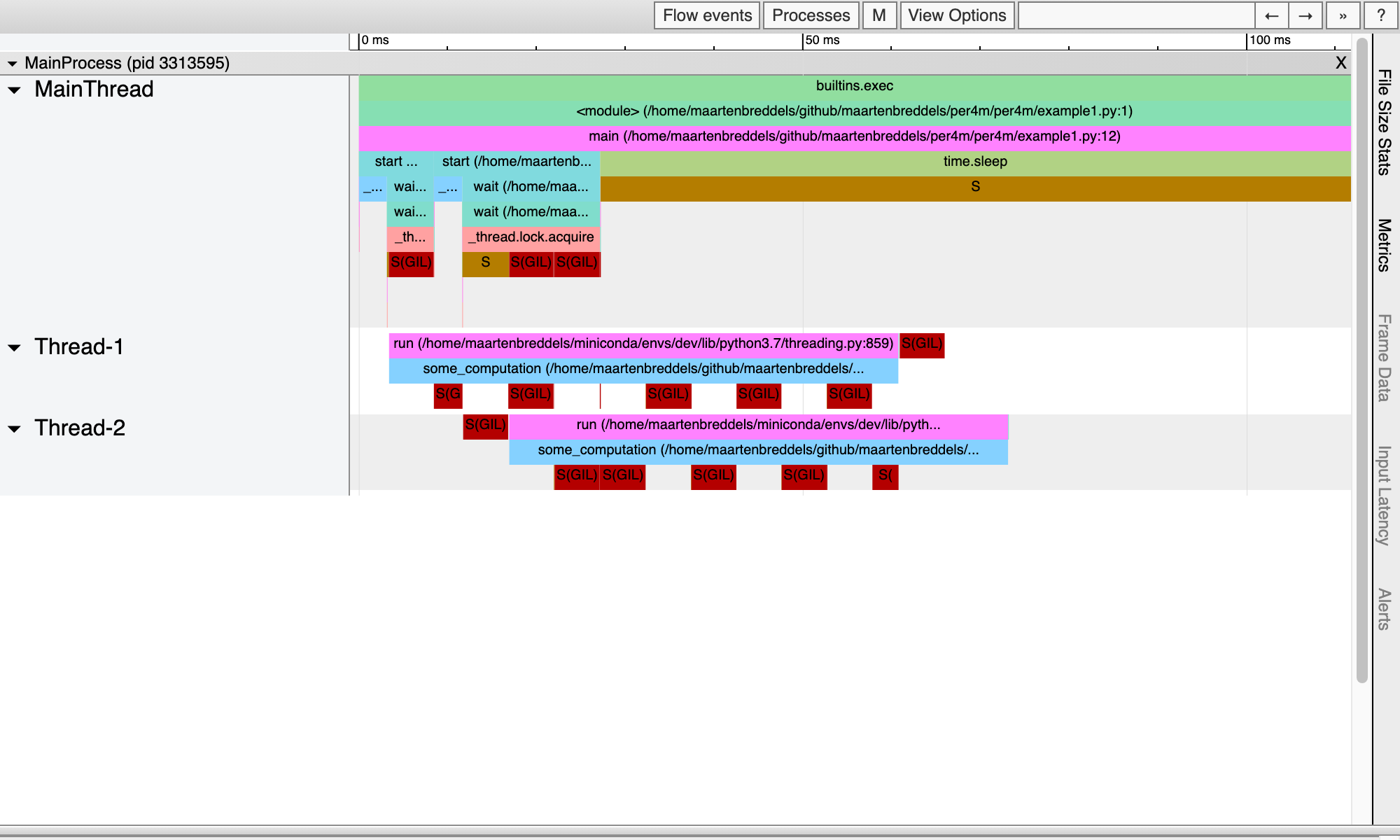
Now we really see where the GIL plays a role!
Via probes (kprobes/uprobes)
We now know when processes are sleeping (due to the GIL or other reasons), but if we want to get a more detailed look at where the GIL is taken or dropped, we need to know where take_gil and drop_gil are being called as well as returned. This can be traced using uprobes via perf. Uprobes are probes in userland, the equivalent to kprobes, which as you may have guessed operate in kernel space. Julia Evans is again a great resource.
Let us install the 4 uprobes:
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
Added new events:
python:take_gil (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:take_gil_1 (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil_1 -aR sleep 1
Failed to find "take_gil%return",
because take_gil is an inlined function and has no return point.
Added new event:
python:take_gil__return (on take_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil__return -aR sleep 1
Added new events:
python:drop_gil (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:drop_gil_1 (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil_1 -aR sleep 1
Failed to find "drop_gil%return",
because drop_gil is an inlined function and has no return point.
Added new event:
python:drop_gil__return (on drop_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil__return -aR sleep 1It complains a bit and seems to add multiple probes/events because drop_gil and take_gil are inlined (which means the function is present multiple times in the binary), but it seems to work 🤷 (let me know in the comments if it does not work for you).
Note that the probes cause no performance hit, only when they are 'active' (like when we monitor them under perf) will the trigger a different code path. When monitored, the affected pages for the monitored process will be copied, and breakpoints are inserted at the right locations (INT3 for x86 CPUs). The breakpoint will trigger the event for perf, which causes a small overhead. In case you want to remove the probes, run:
$ sudo perf probe --del 'python*'Now perf understand new events that it can listen to, so let us run perf again with -e 'python:*gil*' as extra argument
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' -k CLOCK_MONOTONIC \
-e 'python:*gil*' -- viztracer -o viztracer1-uprobes.json --ignore_frozen -m per4m.example1--call-graph dwarf otherwise perf cannot keep up, and we will lose events.
We then use per4m perf2trace to convert this to a JSON that VizTracer understands, while we also get some free statistics.
$ perf script --no-inline | per4m perf2trace gil -o perf1-uprobes.json
...
Summary of threads:
PID total(us) no gil%✅ has gil%❗ gil wait%❌
-------- ----------- ----------- ------------ -------------
3353567* 164490.0 65.9 27.3 6.7
3353569 66560.0 0.3 48.2 51.5
3353570 60900.0 0.0 56.4 43.6
High 'no gil' is good (✅), we like low 'has gil' (❗),
and we don't want 'gil wait' (❌). (* indicates main thread)
...
Wrote to perf1-uprobes.jsonNote that the per4m perf2trace gil subcommand also gives a gil_load like output. From this output, we see that both threads are waiting for the GIL approximately 50% of the time, as expected.
Using the same perf.data file, that perf record generated, we can also generate the thread/process state information. However, because we ran without the stacktraces, we do not know if we are sleeping due to the GIL or not.
$ perf script --no-inline | per4m perf2trace sched -o perf1-state.json
Wrote to perf1-state.jsonAt last, we combine the three outputs:
$ viztracer --combine perf1-state.json perf1-uprobes.json viztracer1-uprobes.json -o example1-uprobes.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1-uprobes.html ...
Dumping trace data to json, total entries: 10484, estimated json file size: 1.2MiB
Generating HTML report
Report saved.Our VizTracer output gives us a good overview of who has, and wants the GIL:
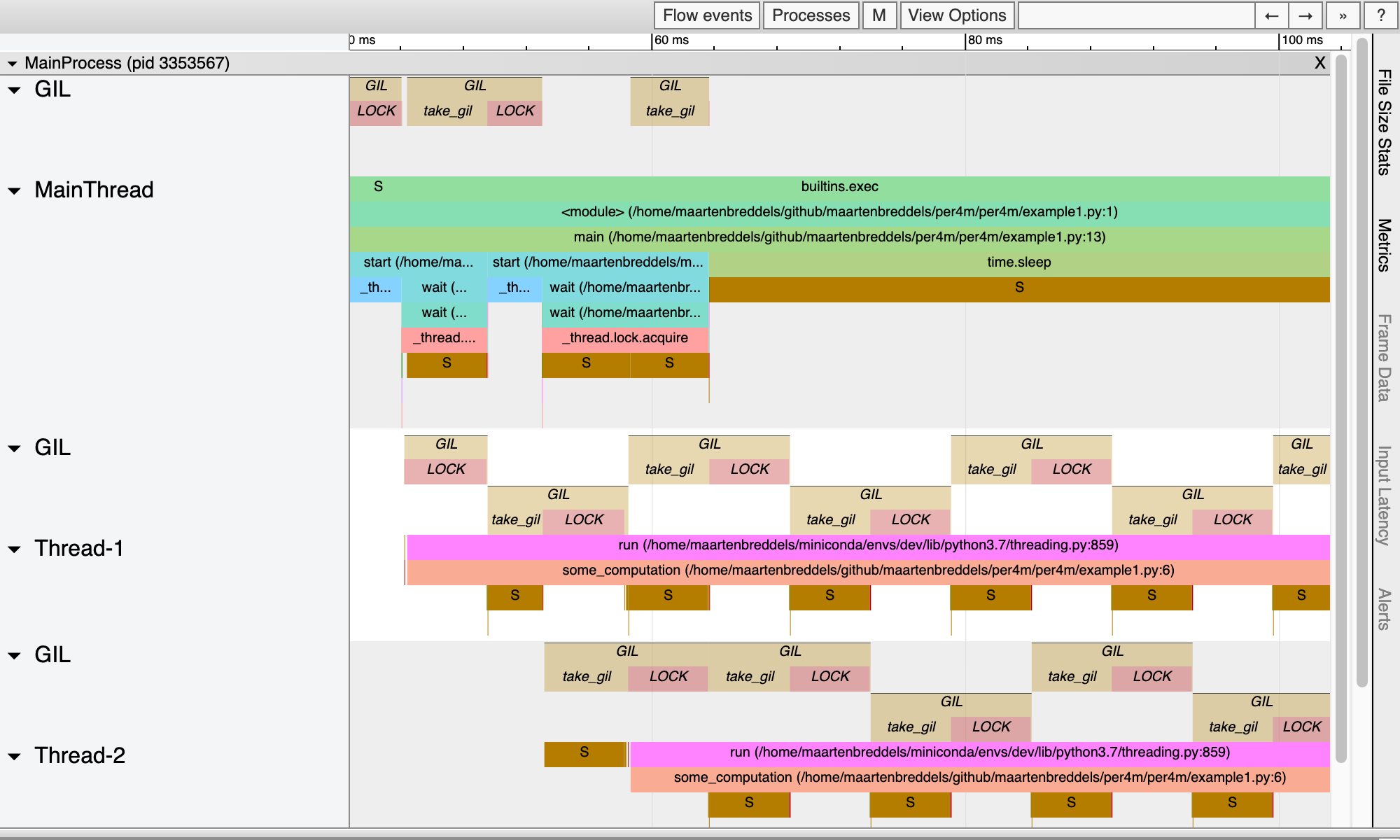
Above each thread, we see when a thread/process wants to take the gil, and when it succeeded (marked by LOCK). Note that these periods overlap with the periods when the thread/process is not sleeping (so running!). Also note that we see only 1 thread/process in the running state, as expected due to the GIL.
The time between each call to take_gil, and actually obtaining the lock (and thus leaving the sleeping state, or waking up), is exactly the time in the above table in the column gil wait%❌. The time each thread has the GIL, or the time spanned by LOCK, is the time in the column has gil%❗.
Releasing the Kraken... ehm GIL
We saw a pure Python program, running multithreaded, where the GIL is limiting performance by letting only 1 thread/process run at a time 1. Let us now see what happens when the code releases the GIL, such as what happens when we execute NumPy functions.
The second example execute some_numpy_computation, which calls a NumPy function M=4 times, in parallel using 2 threads, while the main thread executes pure Python code.
Per Python process of course, and possibly in the future per (sub)interpreter.↩
import threading
import time
import numpy as np
N = 1024*1024*32
M = 4
x = np.arange(N, dtype='f8')
def some_numpy_computation():
total = 0
for i in range(M):
total += x.sum()
return total
def main(args=None):
thread1 = threading.Thread(target=some_numpy_computation)
thread2 = threading.Thread(target=some_numpy_computation)
thread1.start()
thread2.start()
total = 0
for i in range(2_000_000):
total += i
for thread in [thread1, thread2]:
thread.join()
main()
Instead of running this script using perf and VizTracer, we now use the per4m giltracer util, which automates all the steps done above (in a slightly smarter way1):
$ giltracer --state-detect -o example2-uprobes.html -m per4m.example2
...
Summary of threads:
PID total(us) no gil%✅ has gil%❗ gil wait%❌
-------- ----------- ----------- ------------ -------------
3373601* 1359990.0 95.8 4.2 0.1
3373683 60276.4 84.6 2.2 13.2
3373684 57324.0 89.2 1.9 8.9
High 'no gil' is good (✅), we like low 'has gil' (❗),
and we don't want 'gil wait' (❌). (* indicates main thread)
...
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example2-uprobes.html ...
...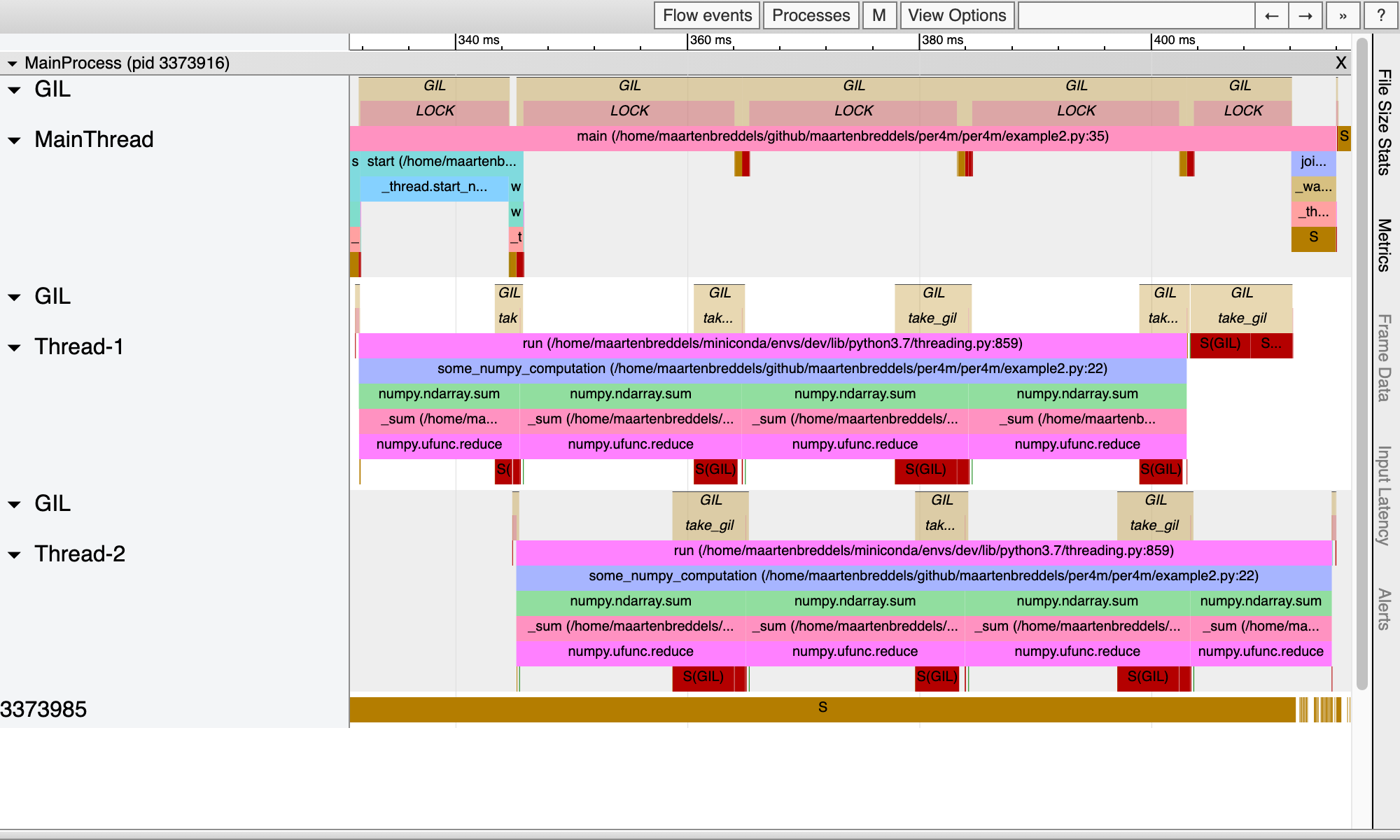
We see that while the main thread is running Python code (it has the GIL, indicated by the LOCK above it), the threads are also running. Note that in the pure Python example we only had one thread/process running at a time. While here we see moments where 3 threads are truly running parallel). This is possible because the NumPy routines that enter into C/C++/Fortran, released the GIL.
However, the threads are still hampered by the GIL, since once the NumPy function returns to Python land, it needs to obtain the GIL again as can be seen by the take_gil blocks taking a bit of time. This causes a 10% wait time for each thread.
We actually start perf twice, once without stacktraces, once with, and we import the module/script before we execute its main function, to get rid of uninteresting tracing information, such as importing modules. This run fast enough that we do not lose events.↩
Jupyter integration
Since my workflow often involves working from a MacBook laptop1 remotely connected to a Linux computer, I use the Jupyter notebook often to execute code remotely. Being a Jupyter developer, creating a cell magic to wrap this was mandatory.
Which does not run perf, but supports dtrace, but this is for another time.↩
# this registers the giltracer cell magic
%load_ext per4m
%%giltracer
# this call the main define above, but this can also be a multiline code cell
main()
Conclusion
Using perf, we can detect process/thread states which gives us an idea which thread/process has the GIL in Python. Using stacktraces, we can find out if the sleeping states are really due to the GIL, and not due to time.sleep for instance.
Combining uprobes with perf, we can trace the calling and returning of the take_gil and drop_gil functions, getting an even better view on the effect of the GIL on your Python program.
The per4m Python package, is an experimental package to do some of the perf script to VizTracer JSON format, and some orchestration tools to make this easier to work with.
TLDR
If you just want to see where the GIL matters:
Run this once:
sudo yum install perf
sudo sysctl kernel.perf_event_paranoid=-1
sudo mount -o remount,mode=755 /sys/kernel/debug
sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"Example usage:
# module
$ giltracer per4m/example2.py
# script
$ giltracer -m per4m.example2
# add thread/process state detection
$ giltracer --state-detect -m per4m.example2
# without uprobes (in case that fails)
$ giltracer --state-detect --no-gil-detect -m per4m.example2Future plans
I wish I did not have to develop these tools, and hope I inspire other to build better tooling, that will deprecate mine. I want to write high-performance code, and focus on that.
However, I do see some options that I plan to write about in the future:
- Expose hardware performance counter in VizTracer, to see for instance cache misses, or CPU stalling.
- Inject Python stacktraces into perf stacktraces, so we can combine them with tools from http://www.brendangregg.com/ .e.g. http://www.brendangregg.com/offcpuanalysis.html
- Repeat the same exercise using dtrace for usage under MacOS.
- Automatically detect which C function does not release the GIL (basically autodetect https://github.com/vaexio/vaex/pull/1114 https://github.com/apache/arrow/pull/7756 )
- Apply these to more issues, like in https://github.com/h5py/h5py/issues/1516
If you have other ideas, want to pick some of this up, leave a message or contact me.